PROCESS
getcaptions
Automatically generates captions from image datasets for use in model training. Eliminates the manual process of writing descriptive text for training data, enabling rapid dataset preparation for custom model development.

Fig 2: getcaptions generates machine-captioned training data for model development from a folder of images
ostris_trainer
Sends captioned datasets to ostris-ai-toolkit (replicate API), returns custom LoRA models in .safetensors format. Together with getcaptions, transforms a single folder of images into personalized models for immediate deployment, eliminating manual training configuration and file management.
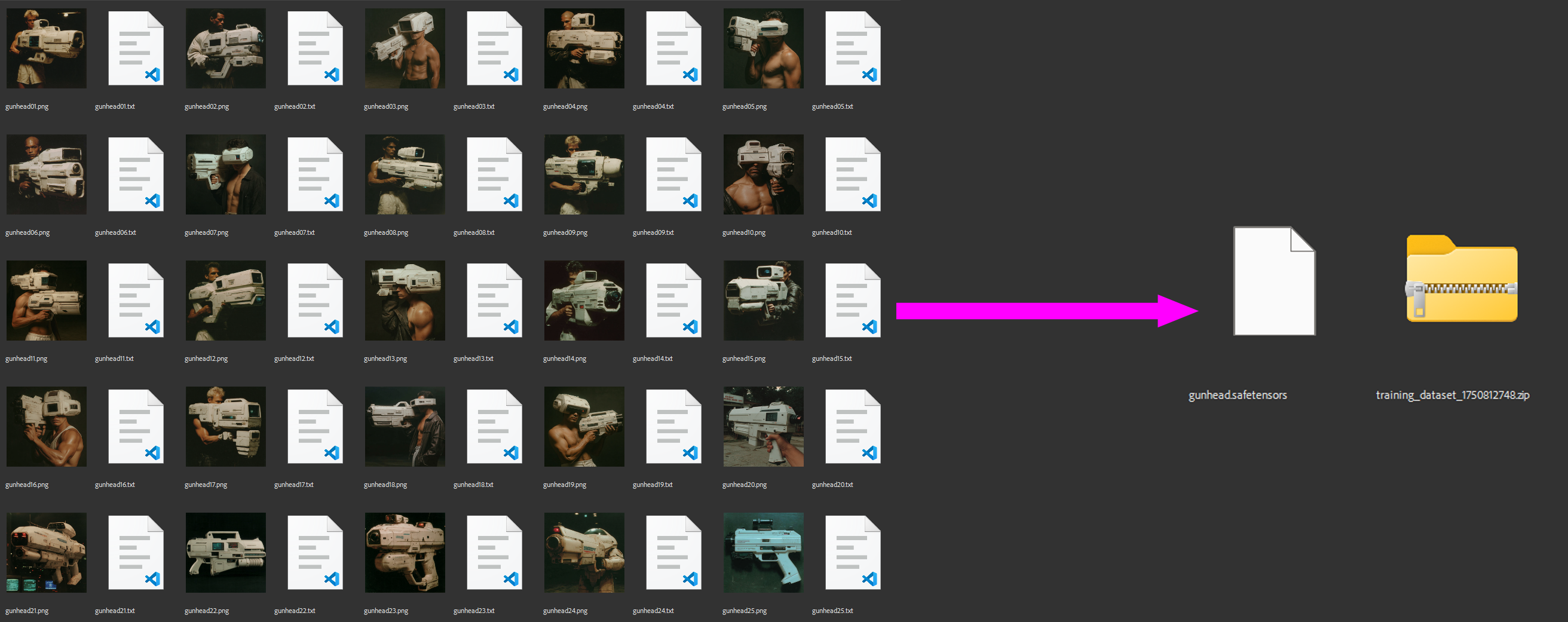
Fig 3: ostris_trainer automates the complete training pipeline from captioned data to production-ready LoRA models
augmentprompt
Automatically transforms simple user inputs into detailed, optimized prompts for different models and use cases. Supports image, video and audio modalities, eliminating manual prompt engineering across platforms.

Fig 4: augmentprompt expands minimal input into optimized prompts tailored for specific AI models and modalities
viewcomfy_api
Sends prompts to a custom ComfyUI deployment running personalized workflows and LoRA models. This creates a dedicated image generation service tailored to specific creative requirements, accessible through CLI. Rather than being limited to standard AI platforms, the system provides programmatic access to custom-trained models and workflows for consistent, personalized image generation without manual ComfyUI interaction.

Fig 5: viewcomfy_api provides CLI access to a custom image generation service running personalized ComfyUI workflows and LoRA models
magnific_upscale
Sends images to Magnific via Freepik API, returns enhanced images. Integrates seamlessly into automated workflows with concurrency support, configurable parameters. Eliminates manual image enhancement steps.

Fig 6: magnific_upscale enhances images through Magnific, with concurrent batch operations
getvideo
Sends image and prompt to video models via fal API, returns video files. Supports Kling1.5-2.1, Hailuo 2.0, and Seedance with configurable parameters including duration, end-frames, and loops. Features concurrent worker support for batch processing.
Fig 7: getvideo generates video content from images and prompts across multiple AI video platforms
getaudio
Sends video files and prompts to MMAudio v2 model via fal API, returns videos with synchronized generated audio. This handles the complexity of video file transmission and processing, creating contextually appropriate sound effects that match video content. Integrates directly with the video pipeline to eliminate manual audio editing and synchronization. Supports concurrent requests.
autopost
Automatically applies post-production to local video files including color-correction, sharpening, and vignette via ffmpeg; upscaling/interpolation via Topaz (CLI or API); high-quality analog film grain (configurable); and optimal file compression for delivery.
Fig 9: autopost applies multi-stage enhancement including color correction, upscaling, interpolation, film grain, and file compression.


